首先安装必要的库
pip install opencv-python
pip3 install --user numpy scipy matplotlib
pip3 install torch torchvision torchaudio
pip install matplotlib
pip install torchvision训练数字识别模型
"""
****************** 训练数字识别模型 *******************
"""
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 默认显示512张图片
BATCH_SIZE = 512
# 默认训练批次20次
EPOCHS = 20
# 默认使用cpu加速
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 构建数据转换列表
tsfrm = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1037,), (0.3081,))
])
# 由于官方已经实现dataset,直接使用DataLoader来获取数据
# MNIST数据集包含6万张28x28的训练样本,1万张测试样本
# 下载训练集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root = 'data', train = True, download = True,
transform = tsfrm),
batch_size = BATCH_SIZE, shuffle = True)
# 下载测试集
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root = 'data', train = False, download = True,
transform = tsfrm),
batch_size = BATCH_SIZE, shuffle = True)
# 展示训练样本图片
# 使用torchvision.utils中的make_grid类方法将一个批次的图片构造成网格模式
def imshow(images):
img = torchvision.utils.make_grid(images)
npimg = img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
# 从训练集中拿出一批图像
# 用iter和next函数来获取取一个批次的图片数据和其对应的图片标签
images,labels = next(iter(train_loader))
imshow(images)
print(labels)
# 定义一个LeNet-5网络,包含两个卷积层conv1和conv2,两个线性层作为输出,最后输出10个维度
# 这10个维度作为0-9的标识来确定识别出的是哪个数字。
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1*1*28*28
# 1个输入图片通道,10个输出通道,5x5卷积核
self.conv1 = nn.Conv2d(1, 10, 5)
self.conv2 = nn.Conv2d(10, 20, 3)
# 全连接层、输出层softmax,10个维度
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
# 正向传播
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 1* 10 * 24 *24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 1* 10 * 12 * 12
out = self.conv2(out) # 1* 20 * 10 * 10
out = F.relu(out)
out = out.view(in_size, -1) # 1 * 2000
out = self.fc1(out) # 1 * 500
out = F.relu(out)
out = self.fc2(out) # 1 * 10
out = F.log_softmax(out, dim=1)
return out
# 生成模型
model = ConvNet().to(DEVICE)
print(model)
# 构建优化器optimizer,包含一个可进行迭代优化的、包含所有参数的列表
# model.parameters()表示优化的参数,lr表示学习率
optimizer = optim.Adam(model.parameters(),lr=0.0001)
# 定义训练函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# 输入样本和标签
data, target = data.to(device), target.to(device)
# 每次训练梯度清零
optimizer.zero_grad()
# 正向传播、反向传播和优化过程
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
# 打印训练情况
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 定义验证函数
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
# 输入样本和标签
data, target = data.to(device), target.to(device)
output = model(data)
# 将一批的损失相加
test_loss += F.nll_loss(output, target, reduction='sum')
# 找到概率最大的下标
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
# 打印验证情况
print("\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%) \n".format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)
))
# 开始训练模型
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
# 保存模型
torch.save(model.state_dict(), "./MNISTModel.pkl")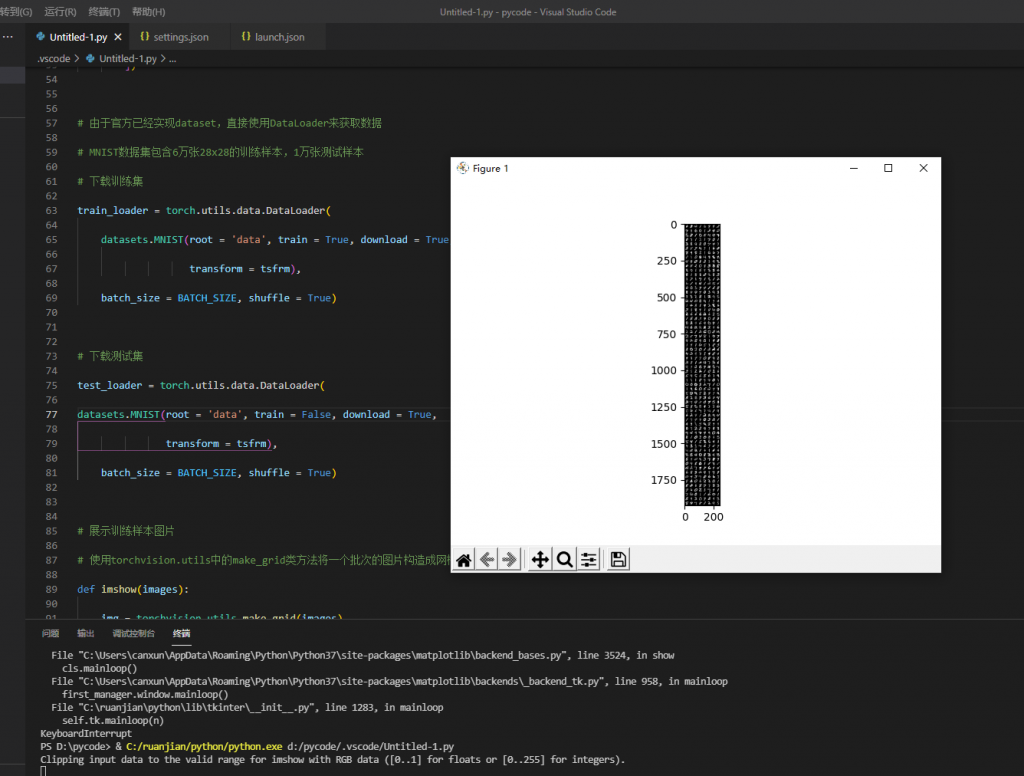
关闭开始训练
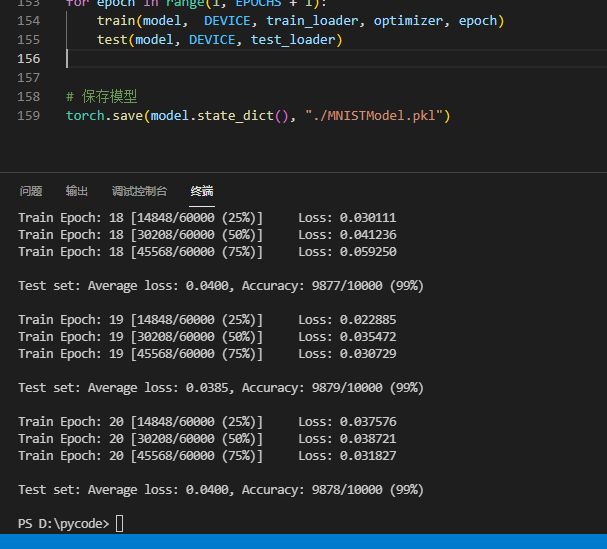
20次训练完成 已保存模型
实现MNIST手写数字识别
"""
****************** 实现MNIST手写数字识别 ************************
****************************************************************
"""
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
# 默认预测四张含有数字的图片
BATCH_SIZE = 4
# 默认使用cpu加速
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 构建数据转换列表
tsfrm = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1037,), (0.3081,))
])
# 测试集
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root = 'data', train = False, download = True,
transform = tsfrm),
batch_size = BATCH_SIZE, shuffle = True)
# 定义图片可视化函数
def imshow(images):
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
# 将图片高和宽分别赋值给x1,y1
x1, y1 = img.shape[0:2]
# 图片放大到原来的5倍,输出尺寸格式为(宽,高)
enlarge_img = cv2.resize(img, (int(y1*5), int(x1*5)))
cv2.imshow('image', enlarge_img)
cv2.waitKey(0)
# 定义一个LeNet-5网络,包含两个卷积层conv1和conv2,两个线性层作为输出,最后输出10个维度
# 这10个维度作为0-9的标识来确定识别出的是哪个数字。
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1*1*28*28
# 1个输入图片通道,10个输出通道,5x5卷积核
self.conv1 = nn.Conv2d(1, 10, 5)
self.conv2 = nn.Conv2d(10, 20, 3)
# 全连接层、输出层softmax,10个维度
self.fc1 = nn.Linear(20 * 10 * 10, 500)
self.fc2 = nn.Linear(500, 10)
# 正向传播
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x) # 1* 10 * 24 *24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) # 1* 10 * 12 * 12
out = self.conv2(out) # 1* 20 * 10 * 10
out = F.relu(out)
out = out.view(in_size, -1) # 1 * 2000
out = self.fc1(out) # 1 * 500
out = F.relu(out)
out = self.fc2(out) # 1 * 10
out = F.log_softmax(out, dim=1)
return out
# 主程序入口
if __name__ == "__main__":
model_eval = ConvNet()
# 加载训练模型
model_eval.load_state_dict(torch.load('./MNISTModel.pkl', map_location=DEVICE))
model_eval.eval()
# 从测试集里面拿出几张图片
images,labels = next(iter(test_loader))
# 显示图片
imshow(images)
# 输入
inputs = images.to(DEVICE)
# 输出
outputs = model_eval(inputs)
# 找到概率最大的下标
_, preds = torch.max(outputs, 1)
# 打印预测结果
numlist = []
for i in range(len(preds)):
label = preds.numpy()[i]
numlist.append(label)
List = ' '.join(repr(s) for s in numlist)
print('当前预测的数字为: ',List)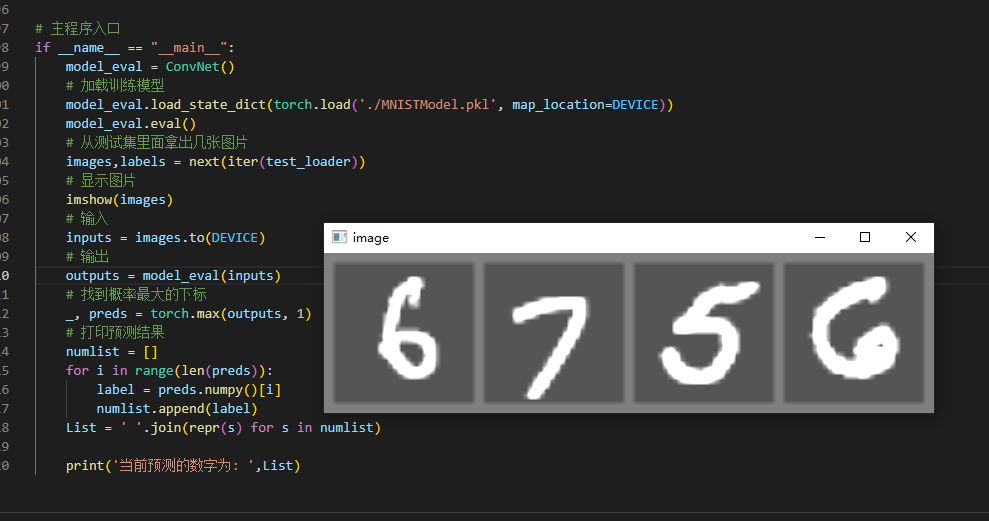
关闭 输出预测的数字


评论 (0)